

Wanted: A "Dumb" Cryptogram-Maker (2 of 2)
More useful than you might think!

Last time out, I discussed the intrigue of finding words, phrases, and names that had the same letter-patterns, making them act as cryptograms of each other (ALFALFA and ENTENTE, EMMA STONE and GOOD THING). You could also call them isomorphic strings, since “isomorphic” means “identically shaped.”
What would be helpful is an Excel function or an accessible program that could take a long set of strings and turn them into sequence-based code, or “dumb” cryptograms. What do I mean by “dumb”?
To illustrate, here’s the Doyle puzzle again:

The ctyptogram begins with the letter R (standing for the letter I). It could just as easily begin with Z, or H, or F. You don’t usually see cryptogram puzzles that just make the first letter A, the second unique letter B, the third unique letter C, and so on. That would make the above cryptogram—HL HK J TUOJL LGHAT LX KLJUL NHDO VHLG J KQJNN ABQFOU XD UOJNNW TXXY FXXIK VGHZG JUO WXBU MOUW XVA—into this:
AB AC D EFGDB BHAIE BJ CBDFB KALG MABH D CNDKK IONPGF JL FGDKKQ EJJR PJJSC MHATH DFG QJOF UGFQ JMI.
It just looks nicer to mix the letters up more…in a cryptogram puzzle.
But for pattern analysis, that “first is A, second is B, third is C” approach is exactly what’s called for. I can see how it'd work as a series of commands. Here’s one loop-based option:
1. Make all text lowercase
Find first lowercase letter in changed string
Change all instances of that letter to capital A
Find first lowercase letter in changed string
Change all instances of that letter to the first capital letter in the alphabet that isn’t already present
Repeat steps 4 and 5 until out of letters
If there were a program or Excel function that did conversions like that, with results like this…
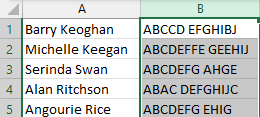
…it’d be easy to identify which strings were isomorphic, just by sorting the B-column and identifying any identical values.
And you’d have data you could work with on grander scales. Beyond goofy exercises like mine, data about isomorphic strings could help us understand other aspects of languages and cryptography.
We could start in on the higher math of studying patterns themselves. Do certain kinds of patterns show up more often in first names than in dictionary words? In fifth-grade vocabulary than in eighth-grade vocabulary? In French than in English?
How many other sciences would benefit from an easy way to break data down into such patterns? I feel like specialist researchers must have some ways to do that of which I’m not aware.
But for word researchers at least, no such solution seems to exist. There’s a gap in the available tools.
So how do we close it?
Years ago, I spotted a similar gap and called on programmers to fix it. That worked out really well! Adam Rosenfield and later Alex Boisvert created a tool I used for over a decade (which is basically part of Wordlisted’s toolset now). So I figured I’d try it again. Here’s what I said then:
Attention, programmers. I will pay a $100 bounty to the first person who produces such a tool, releases it to the public, and lets me know. You are permitted to make money from the tool in other ways, such as sales, shareware and on-site advertising. The bounty’s just to cover what I expect should be a mere few hours of programming time for experienced hands. Let’s make this happen!
To adjust for inflation, this time I’ll kick the bounty up to $134.
Let’s make this happen!
i know of https://www.quinapalus.com/cgi-bin/qat which has exactly the functionality that youre describing... but you cant use your own dictionary
so in theory it is possible